In an earlier post Correctly Matching Xilinx Native FIFOs to Streaming AXI FIFOs,
I mentioned the advantages of interconnecting Xilinx's Native FIFOs to AXI-Streaming
FIFOs and some special considerations on how to do it. Now, I would like to show
a simple architecture to use the DDR3 memory as a Native FIFO.
The intention of this post is to show a possible implementation for creating a
DDR3 Memory Controller which effectively remove from the end user the address
handling for read and write operations and simply delivers a FIFO behaviour to
the end user. There are many advantages on using a large DDR3 Memory (in the
range of 1 to 4 GB) as regular FIFO. RAM Memory blocks on FPGA devices are very
limited, therefore it is often required to use external devices for such purpose.
FIFOs are tipically used in FPGA designs as temporal buffers to accomodate temporal
waiting states from the different logic blocks. It provides a great oportunity
to cross clock domains as well. But in general they are very useful when we would
like to buffer detector data which later will be used as part of an algorithm
calculation when all calculations have concluded and then it is required to
substract the original value from the calculated data several clock cycles after
the original value arrived.
In this scenario, the limiting factor comes from the size of the FIFO that could
be implemented entirely inside an FPGA. Internal storage is very small (~tens of MB)
and therefore the need of designing a simple comtroller for encapsulating DDR3
transactions into input and output FIFO ports.
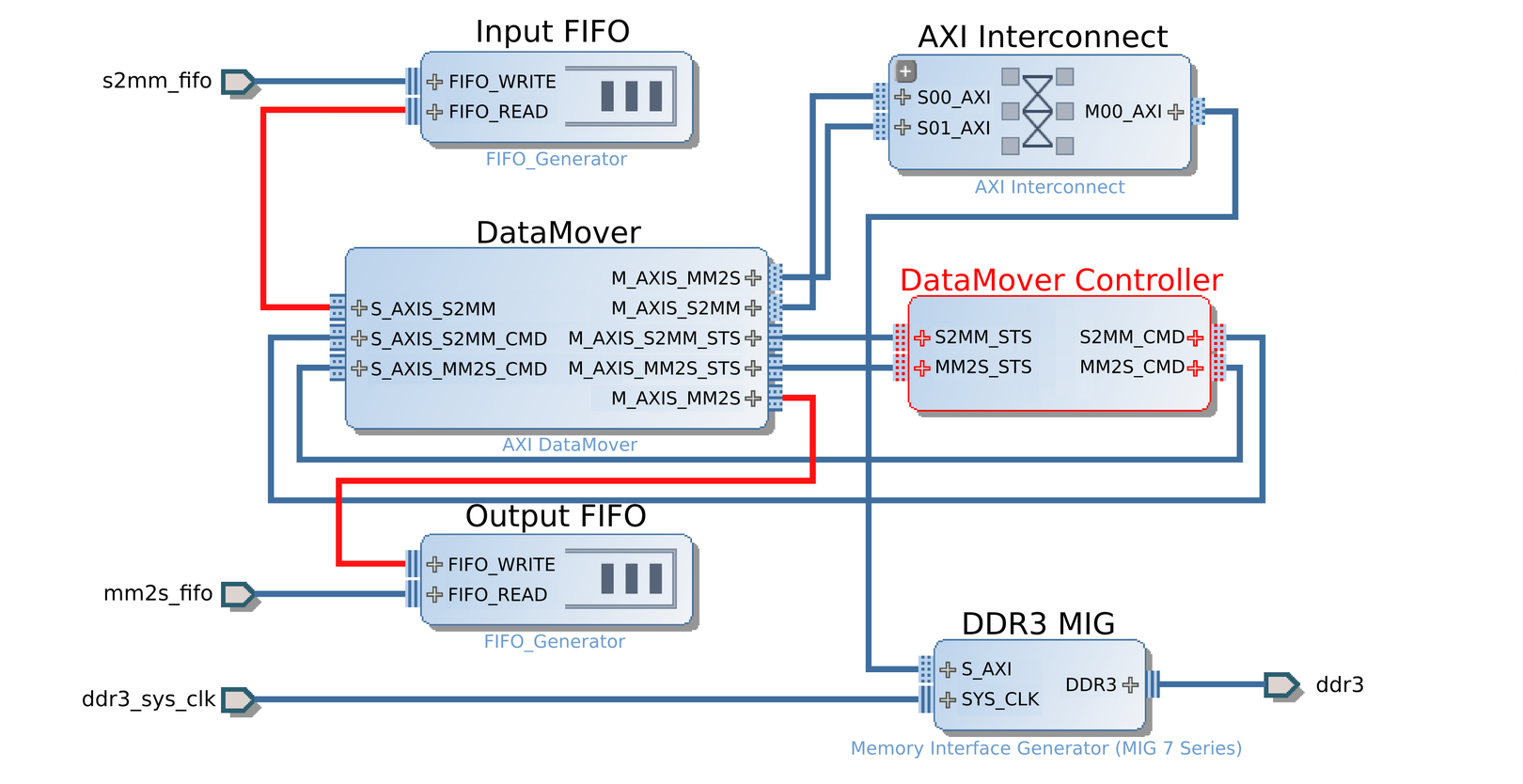
Using the Xilinx IP integrator tool, the previours design was implemented along
with a custom FSM (represented by the DataMover Controller Block in the image)
to control the data flow written in Verilog and integrated
with the rest of the block design. The Verilog file contains two simple state
machines for writing and reading operations of the DDR considering the current
status of the input and output FIFOs.
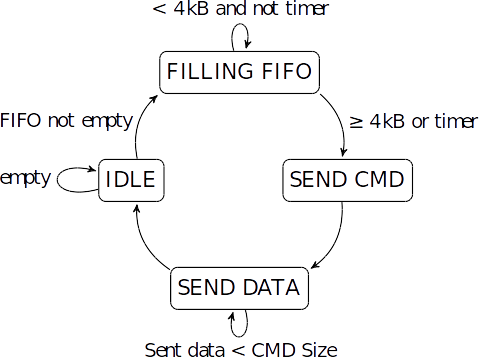
The transfer of data from the input FIFO to the S2MM AXI-S port of the DataMover
is managed by the state machine mentioned above. When the input FIFO is empty the
FSM remains in the IDLE state. Once some data has arrived it moves to the
FILLING FIFO state where it waits until one of two conditions are met.
First the data size contained in the input FIFO has to be greater or equal to
4 kB or second the Timer signal has reached its maximum value.
If one of those two conditions are met, then the FSM proceeds to the SEND CMD
and SEND DATA states. The timer signal allows the system to not remain locked in
case that less than 4 kB of data have arrived. The filling level of the FIFO is
measured using the "More Accurate Data Counts" feature available in the
"First Word Fall Through" FIFO. In this way there is an accurate representation
of the data contained inside and therefore the size of the data to transfer can
be calculated appropriately.
In the SEND DATA state the FSM issues read requests to the input FIFO and sends
the data to the AXI-S interface of the DataMover following the special
considerations mentioned in Correctly Matching Xilinx Native FIFOs to Streaming AXI FIFOs.
The FSM takes care that the exact size of data declared in the SEND CMD state is
read from the FIFO and transfered to the DataMover. Once the data has been transfered
in its totality the state machine goes back to the initial IDLE state. It is also worth
mentioning that the FIFO can receive more data at the same time it is reading and
transferring to the DataMover. The state machine allows an accurate data size management
so that no data is repeated or lost during the transmission, accurate data counters
also provide a higher level of reliability to the overall transfer.
The state machine will remain in the IDLE state until the writing address pointer
is different from the reading address pointer. When the FSM is in the SEND CMD
state it sends a read request with the appropriate size, but if the data to be
read is larger than 8 MB, it is necessary to issue multiple commands with maximum
"bytes to transfer" (bbt) being 8 MB. This limitation comes from the DataMover itself,
the command have only 23 bits for the bbt parameter.